
Like many of you who have been in tech for a while, I keep a pretty hefty private wiki with all the lessons I’ve learned and the platforms I’ve worked with over the years. My database contains thousands of pages – not all of them useful, mind you – and it spans topics ranging from notes on SPB when I was studying for the HPE MASE to documentation on my DIY efforts around the house.
My database structure was getting dense and convoluted as the years went on. While I could search for keywords it was getting harder and harder to find the exact details I needed in the heat of the moment. I wanted the ease of AI-based search, but I didn’t want to share all my notes with a public provider – I wanted this to be self-hosted. That’s what led to this project to build a locally hosted RAG, or Retrieval-Augmented Generation system.
Here’s the high-level design of the first phase, spun up on my local Mac Studio:
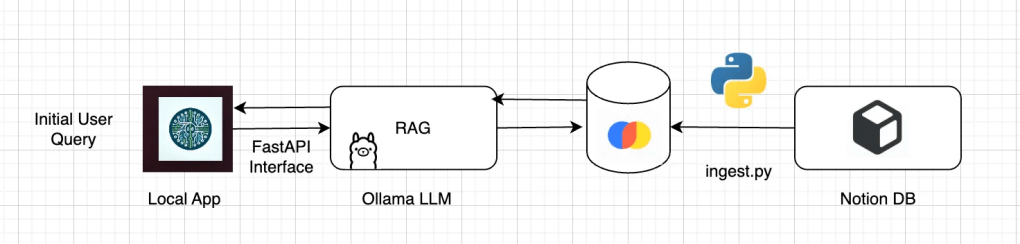
To get started I wrote a script that crawls through the different pages of my database, ingests the text, and then stores the embeddings in Chroma. These embeddings are numerical vectors that represents the semantic meaning of the text – instead of comparing raw words, embeddings let you compare the meanings of phrases in a high-dimensional space, enabling me to search for meaning instead of exact keyword matches. In this case I used nomic-embed-text as the embedding model.
The Ollama llama3.1:8b was chosen as the local LLM as it is well integrated for the Mac development environment. It was given instructions to not try to give an answer that was not included in the context provided from Chroma; it was configured to quickly admit if it didn’t know the answer and the temperature was configured as 0.1 to avoid any overly creative output. This was then wrapped with a FastAPI frontend and I spun up a quick MacOS app for the local user interface.
It was alive! And honestly, working better than I had expected it to work after a little bit of tinkering. Check it out – this is a great example of the RAG summarizing from several sources, pulling from notes written on the same topic across different courses.
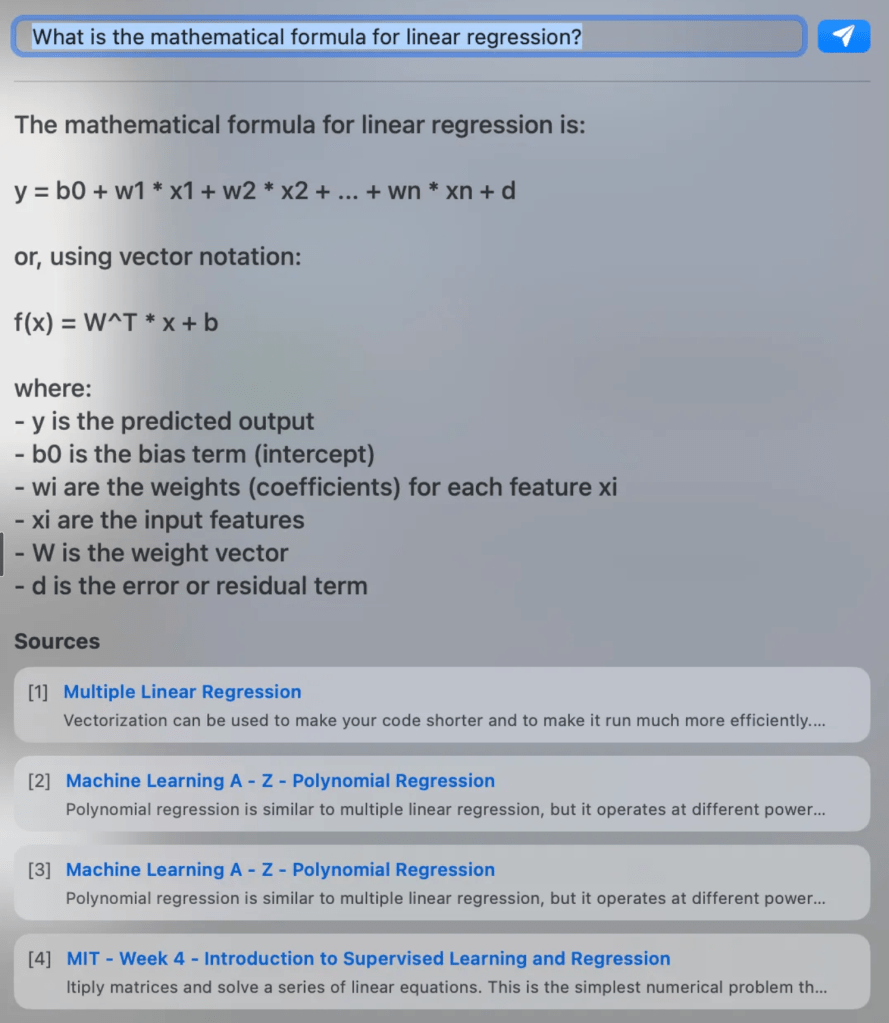
This was a promising start, but after asking several questions it became apparent that a RAG is only as good as the data that supports it. I found that several steps had to be taken to optimize my data pipeline.
- My style of note-taking is outline and bulleted list heavy… and my initial ingestion script did not take this into consideration. It was simply flattening the pages and dicing the text up into chunks; the indentation levels between bullets was not preserved. This had to be corrected in the ingestion process.
- Not everything in my database was text either; there were many screenshots of diagrams and formulae from online classes. Without some form of OCR I was leaving a lot out.
- Embeddings were useful, but sometimes I needed keyword search when dealing with specific acronyms or products. This led to implementing BM25 for keyword search alongside the nomic embeddings and I paired the semantic and keyword search methods together with a reciprocal rank fusion technique.
The ingestion script took a surprising amount of time to dial in. I had a combination of pages and databases, and they were nested together multiple layers deep. And I had it easy compared to many enterprises with only a single source of data.
Ultimately the RAG would sometimes find the answer and other times it would not due to shorthand or a disconnected thought structure / rapid note-taking style. I’m working on improving that as I take notes in the future, but there were some cases where I really needed it to be more flexible and have other sources of information beyond my private wiki.
This led to the next step – moving to an agentic AI framework.
Agentic AI OVERVIEW:
So what is agentic AI? Let’s ask this new local RAG and see what we get!

Not a bad summary. And it’s fairly close – agentic AI allows us to harness the power of LLMs, grant them specific areas of expertise with access to different tools, and tie them together in a collaborative framework.
Here’s the resulting architecture for the new agentic approach running locally on my Mac Studio. You can see that we still start with the RAG as the entry point, but now if the RAG is not sure of the answer given its available context it will pass the request to the general LLM, and if that strikes out it uses Tavily as a quick web summarization tool.
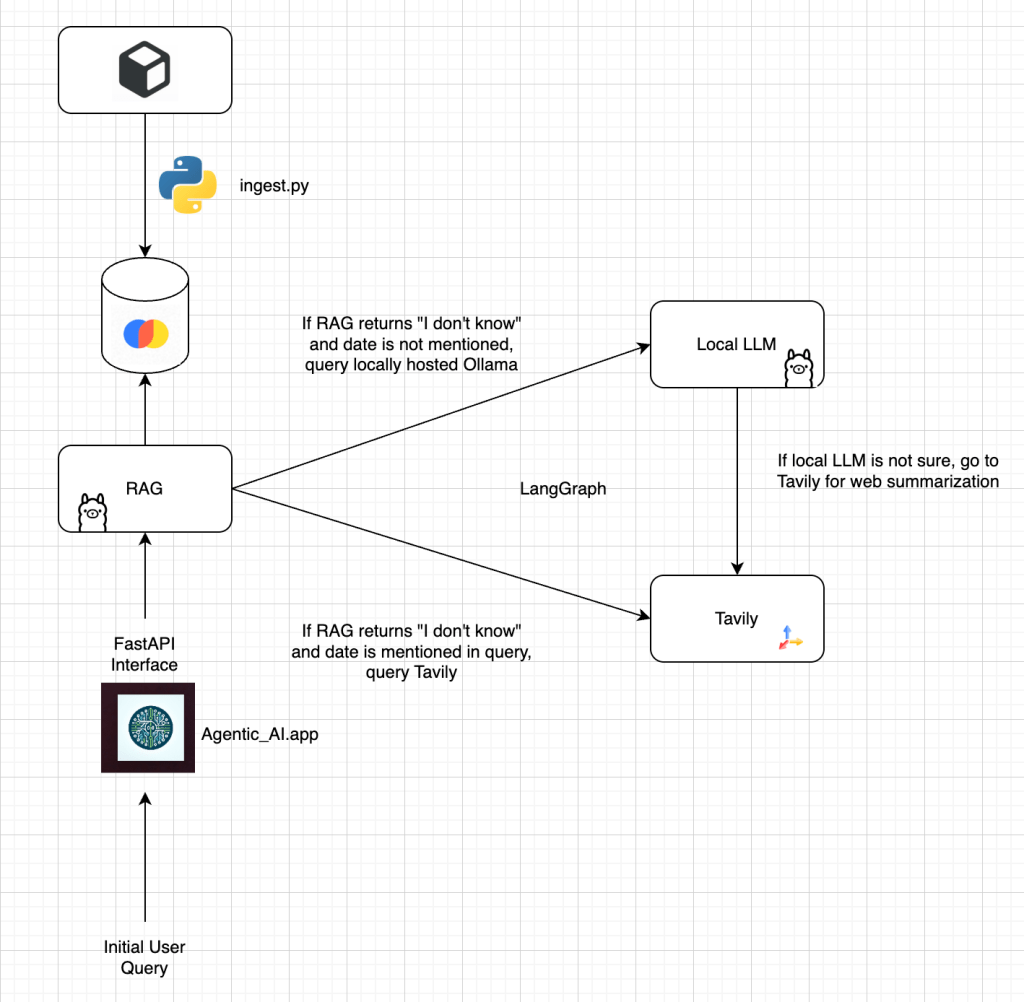
LangGraph is being used to build this framework and to set the collaboration and routing rules between the different agents as they work together to provide an answer to my query. If you’d like to learn more about LangGraph I highly recommend this free course that someone was kind enough to point me towards:
https://academy.langchain.com/courses/intro-to-langgraph
Ultimately, while still very rudimentary / basic, this new architecture gave me something that is more usable than the first pass. I can still ask questions from my local database and it returns a summary along with useful links to the individual Notion pages:

But now if I ask a question that is not in the RAG context LangGraph routes the request to a different agent in the framework. I added a flag into the pipeline that highlights where the answer was ultimately sourced for debugging purposes:
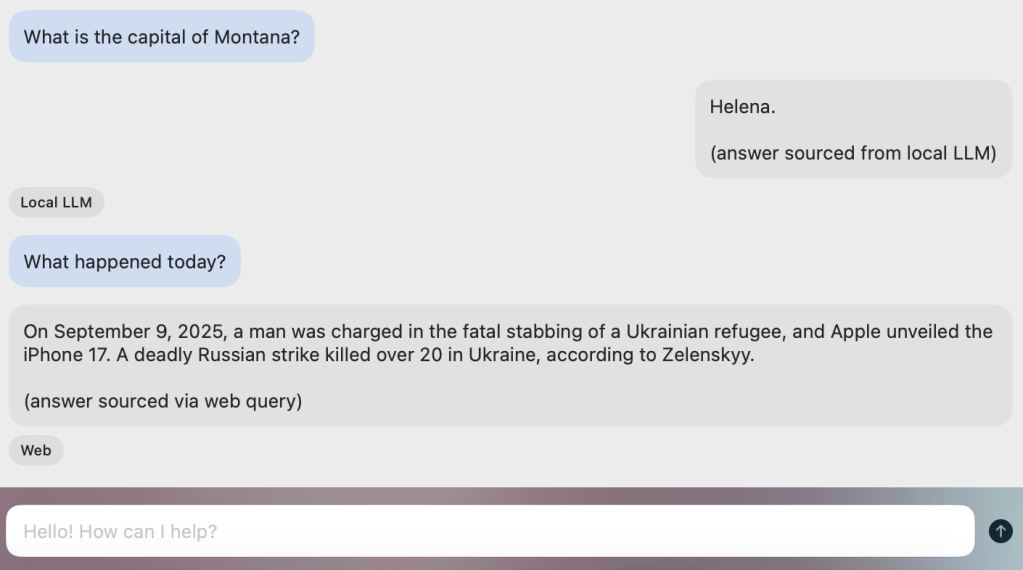
This is just scratching the surface of what is possible – but I wanted to quickly illustrate how agentic AI gives us a lot more flexibility, room for creativity, and potential for collaboration between different AI agents.
APPLYING Agentic AI TO Networking:
So how does all this apply to the networking space? In case you missed it, we recently did a major update to our Marvis VNA to move to an agentic approach – and I’ve been seeing promising results with this new tool out in the field.
Now there are multiple AI agents collaborating together as part of the Marvis VNA, each with their own area of expertise and access to different tools and datasets. I’ve seen this approach automatically build correlations between issues at the WAN Edge that are causing pain for wireless clients, quickly identify the scope of different problems in the environment and provide recommendations for fixes, and much more.
Also, remember earlier how I noted that the biggest pain for me with my own agentic AI framework was the quality of the data that I used to build the project? Mist has been focused on gathering high-quality telemetry data since the creation of the platform. This underlying data gives the new agentic AI framework a very solid foundation.
For example, here’s the ultimate output after asking about application health at a site called “Live Demo” – through the process you can watch the different agents exchange information, find correlations, and then summarize their findings.

If you’d like to learn more about this new agentic approach or if you want to compare notes on building your own local personal assistant please feel free to reach out. Thank you for reading.
